What is BiPaR?
BiPaR is a manually annotated bilingual parallel novel-style machine reading comprehension (MRC) dataset, developed to support monolingual, multilingual and cross-lingual reading comprehension on novels. The biggest difference between BiPaR and existing reading comprehension datasets is that each triple (Passage, Question, Answer) in BiPaR is written parallelly in two languages. We analyze BiPaR in depth and find that BiPaR is diverse in prefixes of questions, answer types and relationships between questions and passages. We also observe that answering questions of novels requires reading comprehension skills of coreference resolution, multi-sentence reasoning, and understanding of implicit causality, etc.
BiPaR Paper (Jing et al. EMNLP '19)
BiPaR Example

Question Types
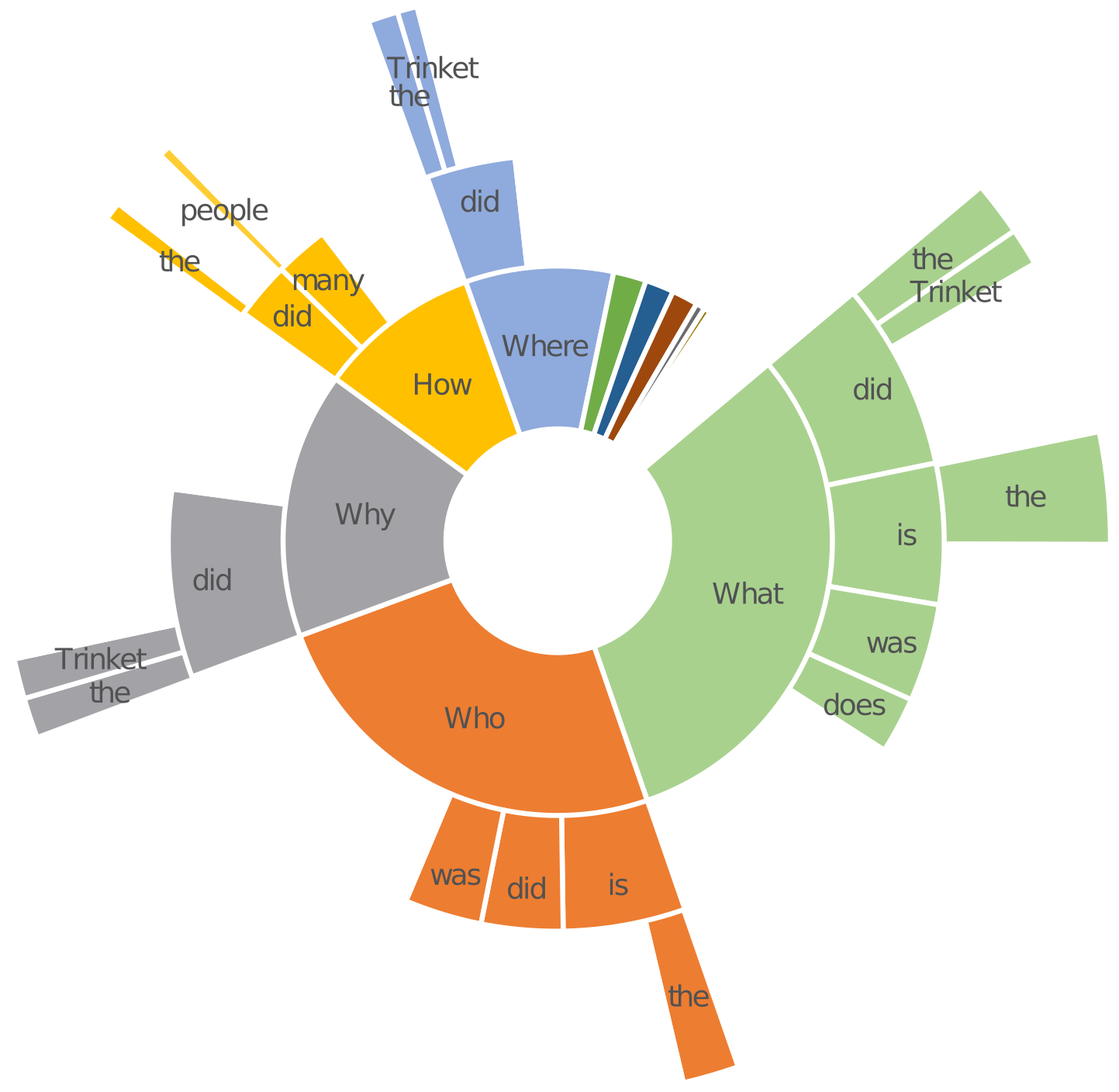
The distribution of trigram prefixes of questions in BiPaR. In particular, BiPaR has 15.6% why and 9.5% how questions. Since in the novel texts, causality is usually not represented by explicit expressions such as “why”, “because”, and “the reason for”, answering these questions in BiPaR requires the MRC models to understand implicit causality.
Getting Started
You can download a copy of the dataset from different task in json format:
License

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License
Have Questions?
For dataset issues, email to yymmjing@gmail.com.
Monolingual Leaderboard
| Rank | Model | EN | ZH | ||
|---|---|---|---|---|---|
| EM | F1 | EM | F1 | ||
| Human Performance | 80.50 | 91.93 | 81.50 | 92.12 | |
|
1 August 26, 2019 |
BERT Large Baseline |
42.53 | 56.48 | - | - |
|
2 August 26, 2019 |
BERT Base Baseline |
41.40 | 55.03 | 48.87 | 64.09 |
|
3 August 26, 2019 |
DrQA Baseline |
27.00 | 39.29 | 37.40 | 53.11 |
Multilingual Leaderboard
| Rank | Model | EN | ZH | ||
|---|---|---|---|---|---|
| EM | F1 | EM | F1 | ||
|
1 August 26, 2019 |
BERT Base Baseline |
38.33 | 51.20 | 49.00 | 64.06 |
|
2 August 26, 2019 |
DrQA Baseline |
28.00 | 42.49 | 36.60 | 53.34 |
Cross-lingual Task1 Leaderboard
| Rank | Model | QZH | QEN | ||
|---|---|---|---|---|---|
|
1 August 26, 2019 |
BERT Large Baseline |
37.53 | 51.51 | - | - |
|
2 August 26, 2019 |
BERT Base Baseline |
32.80 | 46.36 | 39.87 | 53.10 |
|
3 August 26, 2019 |
DrQA Baseline |
21.93 | 34.45 | 27.53 | 41.08 |
Cross-lingual Task2 Leaderboard
| Rank | Model | QZH | QEN | ||
|---|---|---|---|---|---|
|
1 August 26, 2019 |
BERT Large Baseline |
5.60 | 22.29 | - | - |
|
2 August 26, 2019 |
BERT Base Baseline |
5.73 | 21.08 | 7.67 | 20.69 |
|
3 August 26, 2019 |
DrQA Baseline |
7.00 | 18.63 | 4.07 | 16.64 |